

The Writer's Guide to AI Hallucinations
Understanding, Spotting, and Preventing False Information using RADAR Framework


Welcome to the depths, Deep Writers.
Today, we’ll deal with one of the critical challenges writers face using AI: hallucinations — content that sounds reasonable and confident, but is untrue.
If you’ve ever caught your AI assistant confidently citing a non-existent research paper or inventing historical events that never happened, you’ve encountered hallucinations firsthand.
For example, here’s a random quote GPT 3.5 attributed to me:

As writers, we need to be vigilant against hallucinations because random quotes or nonexistent research that make to the final draft are credibility killers.
We are going to go deep into how language models work because having an intuition how these models work and where they falter would help us use them effectively.
By the end of this article, you’ll understand:
Why AI systems hallucinate
A systematic framework for defending against hallucinations
Understanding Tokens: The Building Blocks
Unlike humans who think in words and sentences, AI language models think in tokens — smaller units that can be words, parts of words, or even punctuation marks.
For example, the tokenizers in GPT-4o breaks the sentence “Vigorous writing is concise.” into 7 tokens (each indicated with a different colour):

Click here if you want to see how sentences are tokenized by ChatGPT.
This is how tokenization generally happens:
Common words like “the”, “is”, or “and” are usually single tokens
Longer words get split into multiple tokens: “hallucination” becomes “hall” + “uc” + “ination”
Special characters and spacing matter: “writing;” and “writing ” (with a space) are different tokens
Even capitalization affects tokenization: “Writing” and “writing” are different tokens
The Next-Token Prediction Game
When you prompt an AI, it breaks the input into tokens and predicts the next token based on patterns it has learned during training.
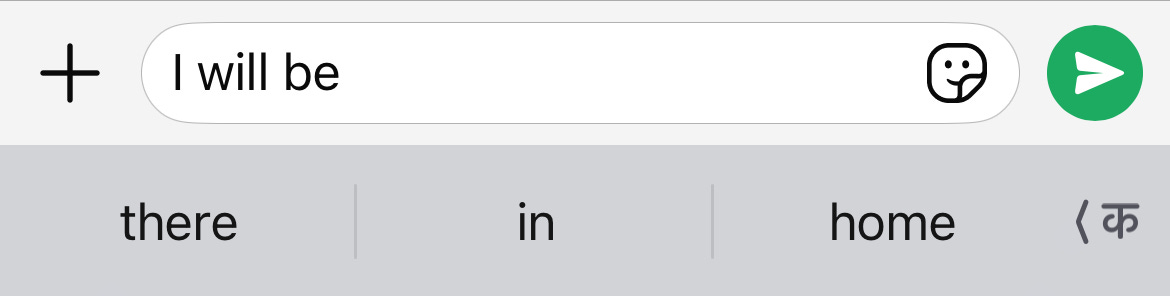
Think of this as a sophisticated autocomplete system, similar to your phone’s text prediction feature. When you type “I will be”, it suggests words like “there” or “home”.
Similarly, when you prompt an LLM: “The most common mistake nonfiction writers make is...”
It isn’t searching through a database of writing advice. Instead, it’s calculating probabilities for the next token based on patterns in its training data:

Based on the patterns the AI has seen, the most probable token after the prompt is “not” (probability of 58.37%), followed by “failing” (probability of 13.71%).
The language model then picks one of the most probable tokens, adds it to the input sequence, and repeats the process.
A couple of interesting things to note here:
The model does not necessarily pick the most likely token.
It might pick a different token the next time for the same prompt.
This built-in randomness is actually one of AI’s most powerful features. If it always chose the most probable token, every response would be predictable and generic.
For example, running the same prompt again produces a completely different output:

Note: There are ways of controlling the randomness. However, it would still not guarantee the same output every time.
The One-Way Street Problem: Hallucinations
Once the AI starts down a particular path, it can’t go back and change a token that came before. If it generates a token that leads it toward mentioning a specific study, it’s now committed to creating details about that study — even if no such study exists.
But, hallucination isn’t a bug — it’s the core mechanism that makes AI writing possible.
As OpenAI co-founder Andrej Karpathy explains, these models are essentially “dream machines.”

Why This Matters for Writers
Understanding this token-prediction mechanism helps us understand that:
The same question asked slightly differently can give very different answers. This isn’t a bug — it’s fundamental to how AI works.
Confidence ≠ Accuracy: An AI’s confident tone comes from generating tokens that commonly follow each other, not from accessing verified information.
More detailed responses aren’t necessarily more reliable. In fact, they often indicate the AI is generating more fictional tokens to maintain consistency.
The Power of Informed Prompting
This understanding highlights the importance of prompt engineering. Using prompt engineering, we can craft prompts that:
Guide the initial token predictions toward reliable patterns
Create checkpoints that force the AI to verify information
Break complex tasks into smaller, verifiable steps
Use specific formatting requirements to constrain hallucinations
Why AI is More Reliable for Some Topics Than Others
Understanding how AI models are trained reveals why they’re more accurate about certain topics and unreliable about others.
Think of AI’s training data as its only “textbook” — an enormous snapshot of the internet and published works that it can never update or fact-check. Once trained, every response the AI generates comes from patterns in this fixed dataset.
The training data typically includes:
About 1/3 internet content (websites, blogs, forums, social media)
About 1/3 scientific papers and academic works
The remaining third split between books, code, conversations, and other texts
This distribution creates interesting “blind spots” and “strong spots” that directly affect when AI is more likely to hallucinate:
Strong Knowledge Areas (Less Likely to Hallucinate)
Common topics with extensive coverage online
Well-documented historical events
Basic concepts in established fields
Standard writing formats and structures
Risky Areas (High Hallucination Potential)
Very recent events (post-training cut-off)
Specific numerical data or statistics
Niche topics with limited online presence
Expert quotes and specific attributions
Cross-disciplinary insights that require connecting disparate topics
The AI would be extremely reliable when explaining basic concepts in psychology (which appear in countless online articles and textbooks) but start inventing plausible-sounding details when asked about a specific psychologist’s views on a niche topic (where the training data might be sparse).
For nonfiction writers, this insight leads to several practical strategies:
Use AI more confidently for broad patterns and general principles
Be extra vigilant when AI discusses specific studies or quotes experts
Consider that the more niche your topic, the more verification you’ll need
The RADAR Framework: Defending Against Hallucinations
Here’s a reliable framework to catch hallucinations before they make it into our work.
R - Recognize Risk Zones
Train yourself to spot two types of content most likely to be hallucinated:
Specific claims (statistics, quotes, study details)
Recent or niche topics
If AI says “According to a 2023 study by Harvard Business Review, 78% of writers report increased productivity using AI,” this needs verification because it combines both specific claims and recent data.
A - Ask for Sources First
Before asking for details, start with:
“What sources would you recommend for learning about [topic]?”
“Who are the key experts in this field?”
Instead of: “What did Simon Sinek say about leadership in his latest book?”
Try: “What books has Simon Sinek written about leadership?”
D - Divide Complex Queries
Break complex queries into basic building blocks:
Start with definitions and core concepts
Build up to specific claims
Instead of: “Explain how meditation affects workplace productivity with relevant research.”
Try:
“What are the basic mechanisms of meditation?”
“How is workplace productivity typically measured?”
“What major studies connect these topics?”
A - Analyze Patterns
Watch for two major warning signs:
Suspiciously perfect examples that tie everything together
Extremely detailed responses to simple questions
If you ask about common writing mistakes and AI responds with an elaborate story about a specific writer complete with detailed quotes and dates — that’s likely fabricated.
R - Require Verification
Focus on two key verification steps:
Google key claims to ensure correctness
Use multiple AI models to cross-check important information.
Claude currently does not have access to the Internet, but GPT-4o does. To cross-check a claim made by Claude, ask GPT to check its authenticity and provide sources.
The Future of AI and Hallucinations
The good news is that AI models are improving and are becoming less likely to hallucinate.
To illustrate this, I tried to get GPT 3.5, GPT 4o, and Claude 3.5 Sonnet to hallucinate (there’s no study done by Dr. Sarah Mitchell on the Pomodoro Technique).
Here are the outcomes:



GPT 3.5 fell into the trap and hallucinated while the latest models (GPT 4o and Claude 3.5 Sonnet) didn’t.
However, while AI models are improving, hallucinations won’t disappear entirely soon. Understanding why they happen and how to handle them is a core skill writers must develop.
Want personalized help implementing AI in your writing process?
I offer 90-minute sessions where we build your custom AI content system together.